들어가면서
- 이전 포스트 에서는
backfill현상에 대해서 알아봤습니다. - 이번에는 제가 cloud watch 를 통해서는 어떤 알람을 걸고 있는지에 대해서 알아보도록 하겠습니다.
- 크게 SQS 에 관련된것과 EC2 에 대한 설정을 하고 있습니다.
SQS Alarm 설정
4가지 알람 설정을 하고 있습니다.
- DLQ 발생
- 오래된 메시지
- 적재된 메시지 개수
- 처리중인 메시지 개수
하나씩 차례대로 어떻게 설정했는지 보겠습니다.
DLQ 발생 알람
- Message Queue(이하 MQ) 에서는 운영환경에서 Dead Letter Queue(이하 DLQ) 설정이 필수 입니다.
- SQS 설정을 할 때도 일정 회수를 시도 후에 처리가 되지 않으면 DLQ로 이동이 되도록 했습니다.
- 이때 DLQ에 메시지가 쌓였다면, alarm 을 받아야 하고 적절한 조치가 필요합니다.
- 필요시에는 DLQ 에 있는 메시지를 원래 Queue 로 보내는 툴이 있어야 합니다.(저는 배치로 만들어 놨습니다.)
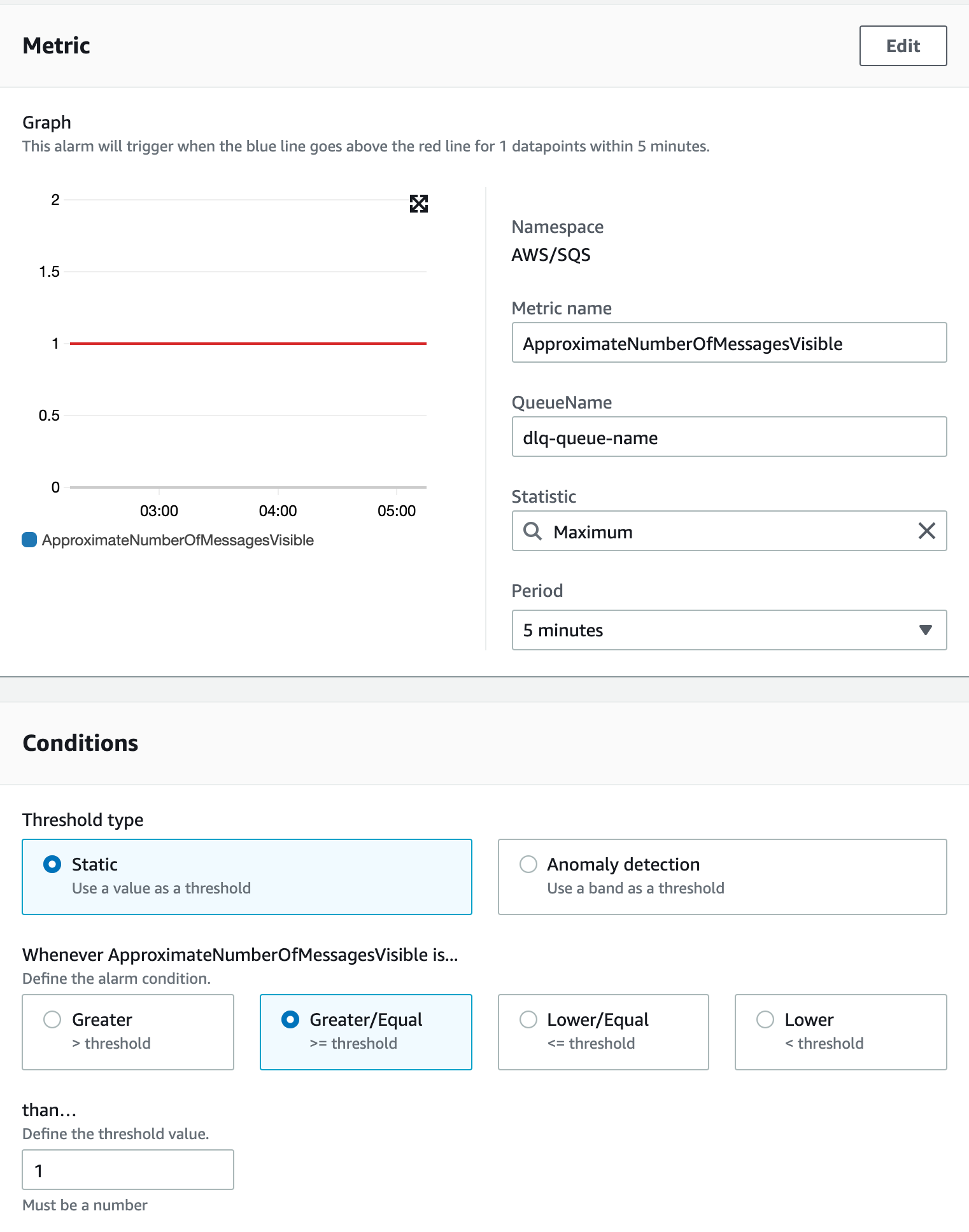
- 필요시에는 DLQ 에 있는 메시지를 원래 Queue 로 보내는 툴이 있어야 합니다.(저는 배치로 만들어 놨습니다.)
오래된 메시지
- 이 상황의 경우 producer 는 메시지를 발송을 하고 있으나, consumer 에서 메시지를 처리를 하지 않고 있는 상황으로 왜 처리를 못하고 있는지를 빠르게 확인하여 조치를 해야합니다.
- consumer 의 경우 더이상 처리가 큐가 필요 없어 SQS 에 있는 메시지 처리를 중단을 한다면 오래된 메시지가 발생이 될 수 있고 이런경우는 적재된 메시지를 삭제 후 SQS를 없애면 됩니다.
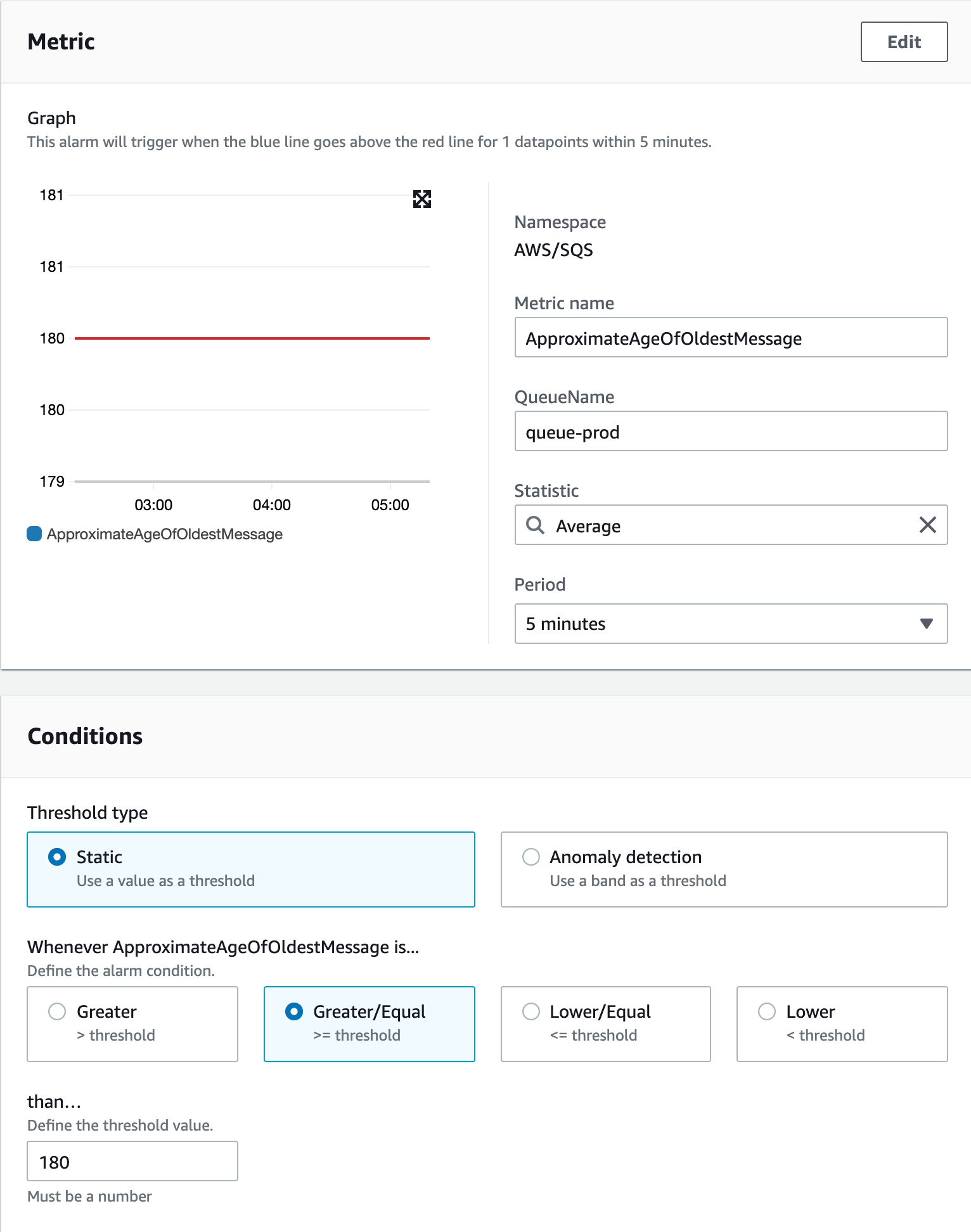
적재된 메시지 개수
- 이 상황은 consumer 가 처리하는 속도보다, producer 가 보내는 속도가 빨라서 점점 메시지 적재되는 개수가 많아지고 있는 현상 입니다.
- consumer 를 늘리던가, 각 consumer 에서 처리하는 메시지의 개수를 늘려주는 등의 조치가 필요합니다.
오래된 메시지에서 설명한 상황에서도 발생할 수 있고 조치는 동일하게 해주시면 됩니다.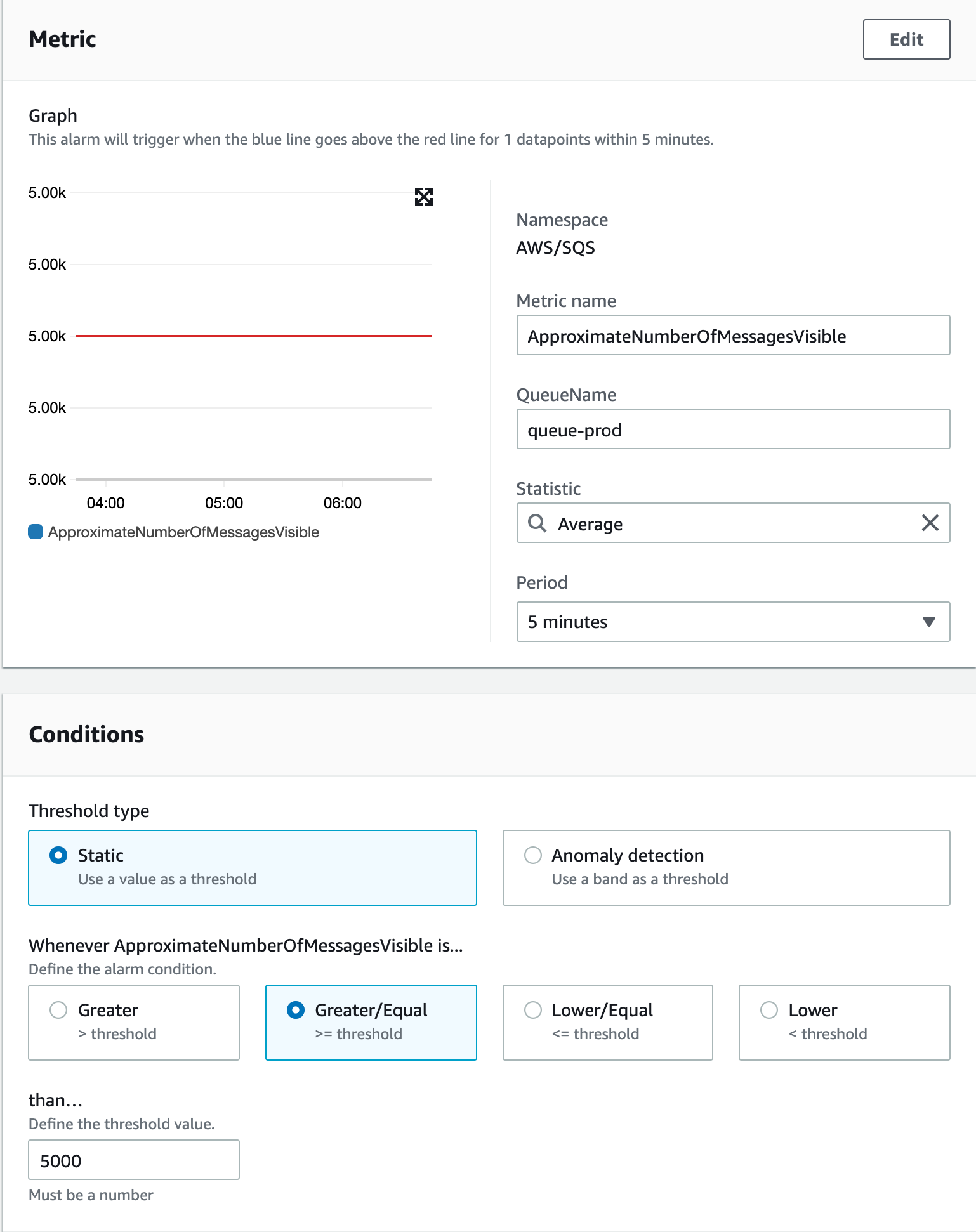
처리중인 메시지 개수
- 이 상황의 경우 consumer 들이 메시지를 수신해서 처리는 하고 있으나, 제대로 처리 했다고 응답이 오지 않은 메시지의 개수를 체크합니다.
- 뭔가 consumer 코드가 잘못배포되어서 메시지 처리 응답이 오지 않는등의 상황을 예상할 수 있겠네요.
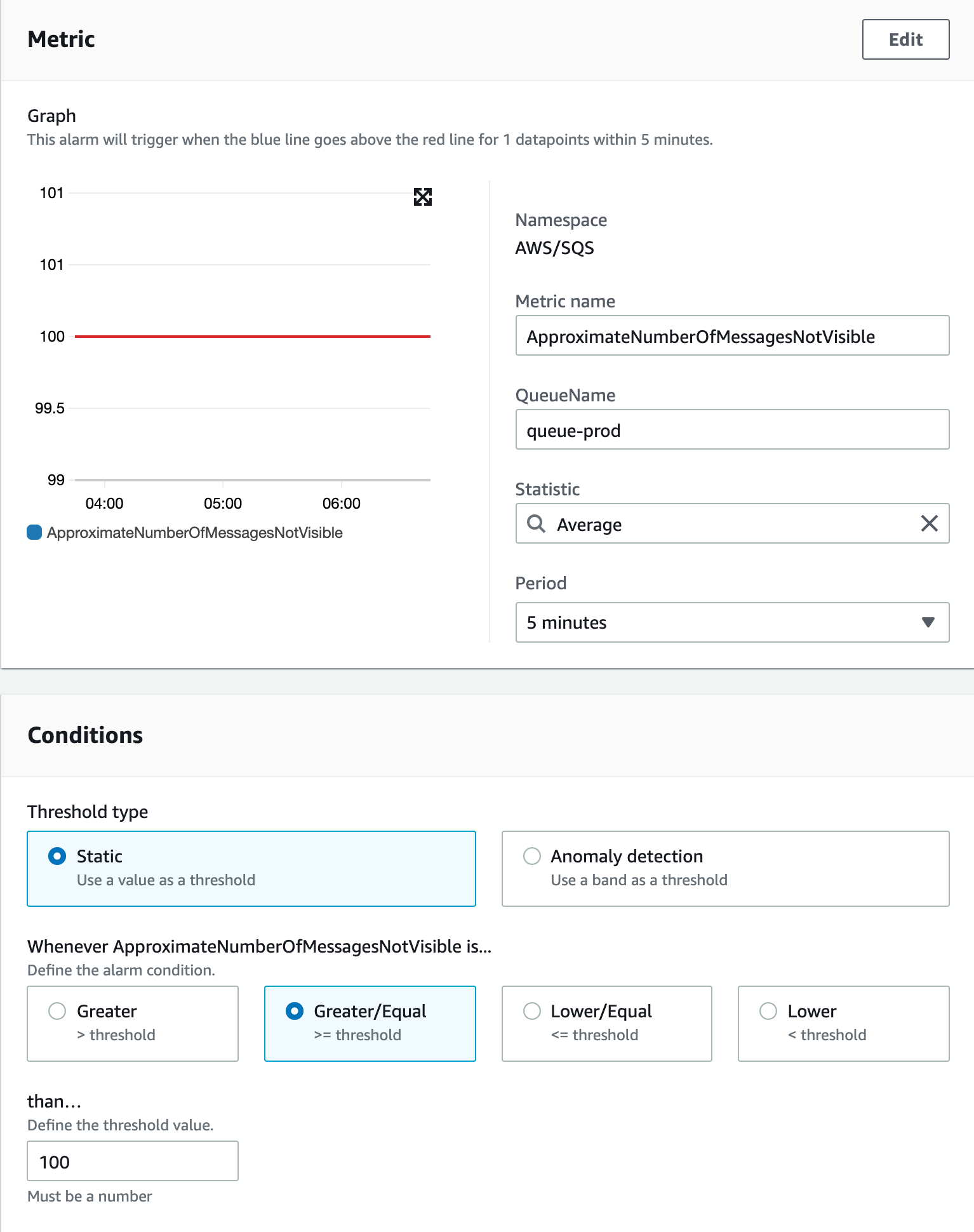
이 이외에 알람 설정
- Amazon SQS CloudWatch 지표 에 보시면 다른 지표들도 있습니다.
- 필요한 지표들을 추가해서 관리하시는 도메인을 안정적으로 서비스 하는데에 보탬이 되었으면 합니다.
- 참고로
1이라고 지표 옆에 윗첨자로 붙어있는건 사용하지 마세요. 상세설명에 적혀 있는 내용을 복사하면 아래와 같습니다.이러한 메트릭은 서비스 관점에서 계산되며 재시도를 포함할 수 있습니다. 이러한 메트릭의 절대값에 의존하거나 현재 대기열 상태를 예측하는 데 사용하지 마십시오.
EC2 알람 설정
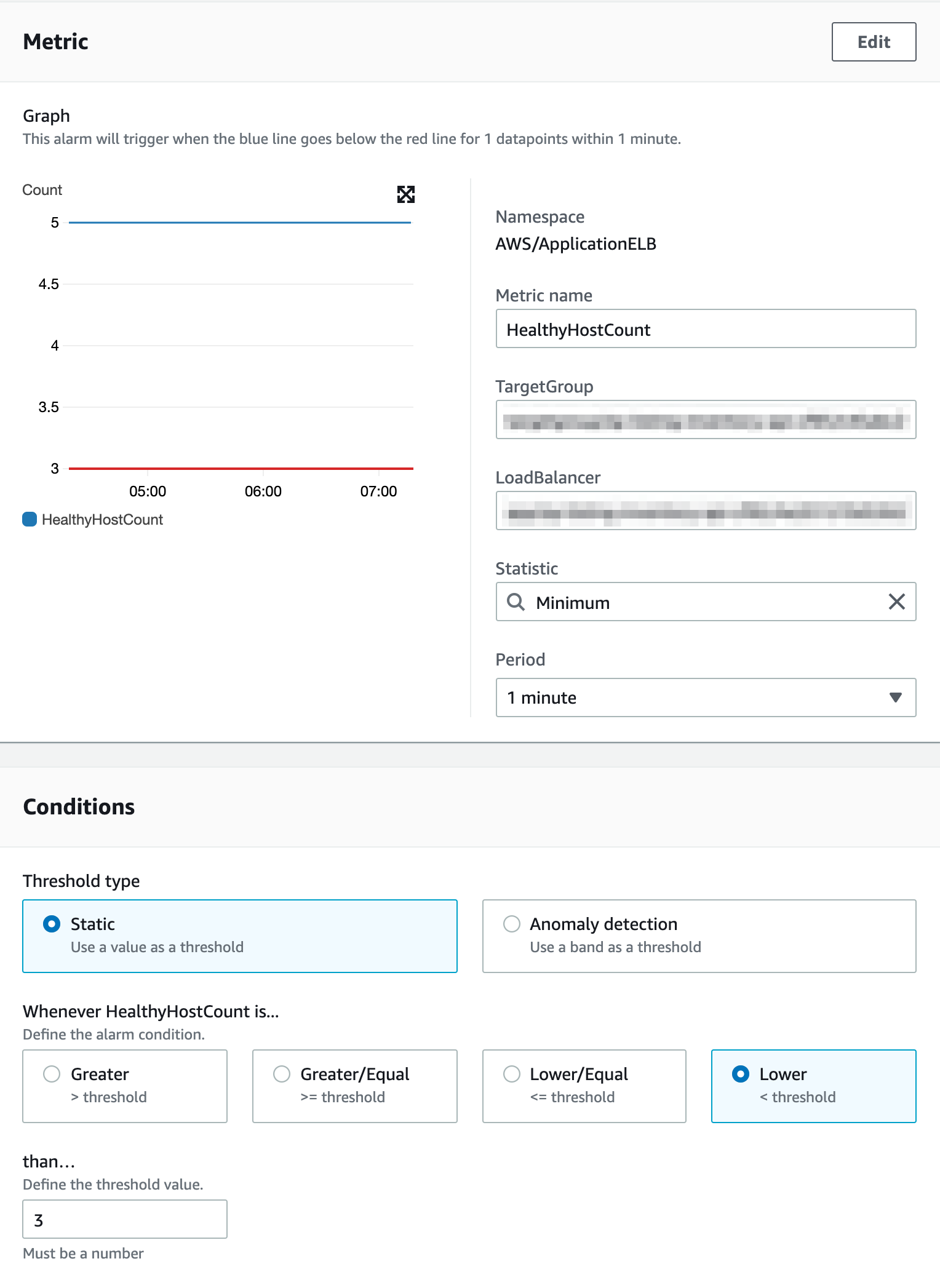
health host
- health host 의 경우 현재 target group 내에 health host 개수를 알 수 있습니다.
- 서비스에서 필요한 최소 EC2를 설정하고, 그 이하로 떨어질 경우 알람을 받아 서비스를 안정적으로 운영 할 수 있습니다.
unhealth host
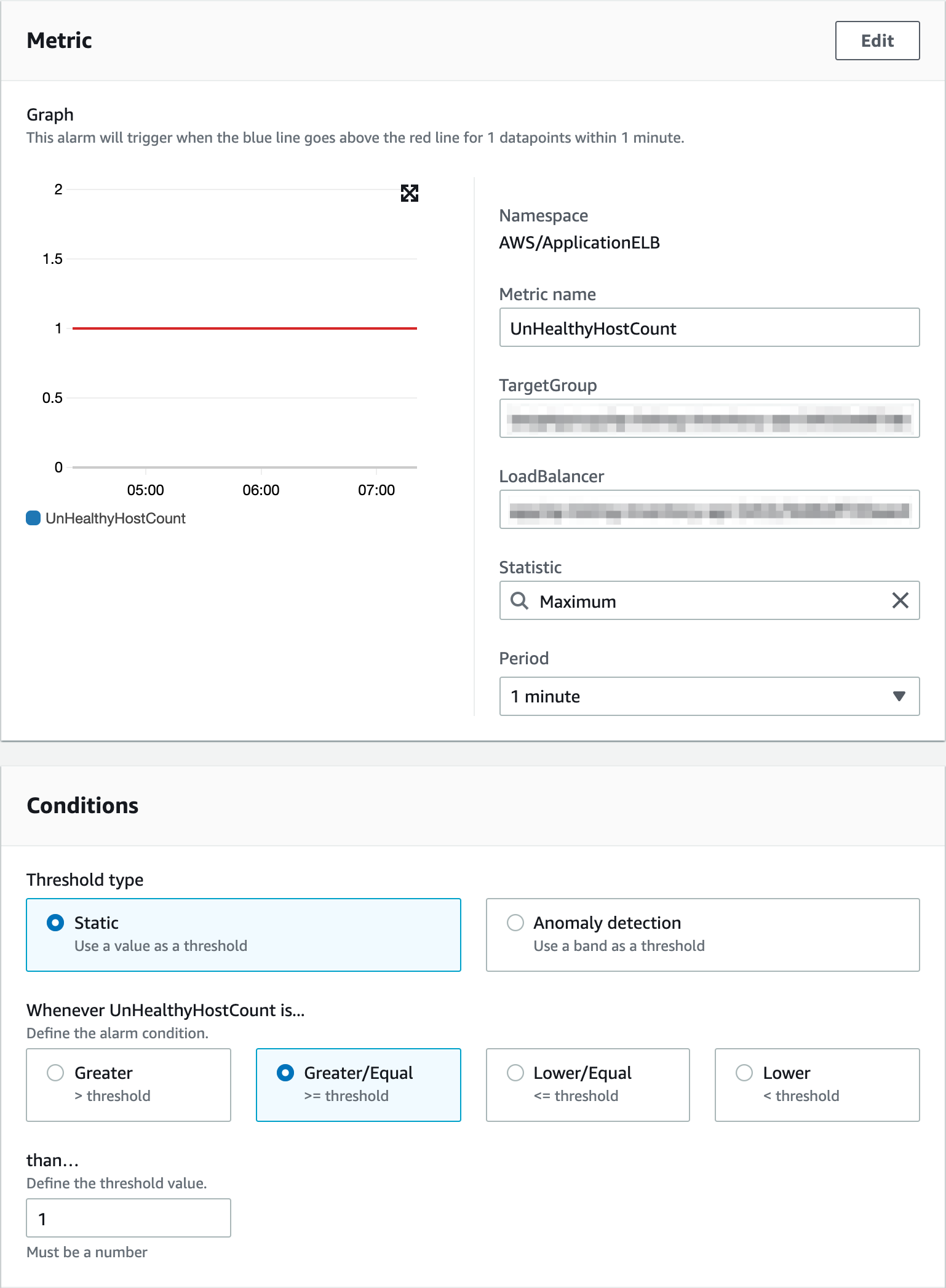
- unhealth host 의 경우 현재 target group 내에 있는 EC2 중에서 unhealth host 개수를 알 수 있습니다.
- unhealth host 알람을 받게 되면, 갑작스럽게 EC2가 unhealth 가 되었을때 바로 대응이 가능합니다.
마치며
- 이밖에도 cloud watch 를 이용해서 다양한 알림을 설정을 할 수 있습니다.
- 저의 경우는 알람을 cloud watch -> SNS -> lambda -> slack 또는 opsgenie 로 알람을 받고 있습니다.
- 감사합니다.
참고 사이트
https://docs.aws.amazon.com/ko_kr/AWSSimpleQueueService/latest/SQSDeveloperGuide/sqs-available-cloudwatch-metrics.html